|
postgibbsf90 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
How does the program
work?
This is an interactive program, so just follow the program. name of parameter file?test.par
Give n to read every n-th sample? (1 means read all samples)
Input files: gibbs_samples, fort.99 output files: postgibbs_samples, postout, postmean, postsd "postgibbs_samples" is a file contaning all Gibbs samples for additional post analyses. "postmean" is a file contaning posterior means. "postsd" is a file contaning posterior standard deviations. "postout":
"Pos.": position of each parameter in the parameter file "eff1" and "eff2": effect number in the parameter file "trt1" and "trt2": trait number in the parameter file "MCE": Monte Carlo Error "Mean": posterior means "HPD interval (95%)": Highest Probability Density "Effective sample size": at least > 10 is recommended. > 30 may be better. "Median": "Mode": when the distribution of the samples is nor normal, there is a difference between "Mode" and "Mean". "Independent chain size": "PSD": Posterior Standard Deviation "PSD interval (95%)": "Convergence diagnostic": ratio between first half and second half of the samples should be < 1.0, but it is not useful because it is < 1.0 most of the time. "Autocorrelations": autocorrelations between two lags. High correlation implies samples are not independent. "Independent # batches": Choose a graph for samples (= 1) or histogram (= 2); or exit (= 0) positions 1 2 3 # choose from the position numbers 1 through 6
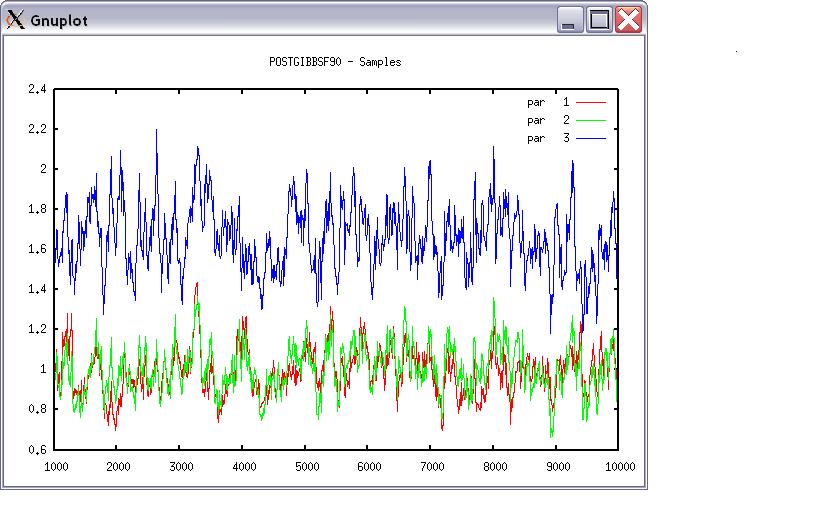
If the graph is stable (not increasing or decreasing), the convergence is met. All samples before that point shoudl be discarded as burn-in. print = 1; other graphs = 2; or stop = 0 Choose a graph for samples (= 1) or histogram (= 2); or exit (= 0) Type position and # bins
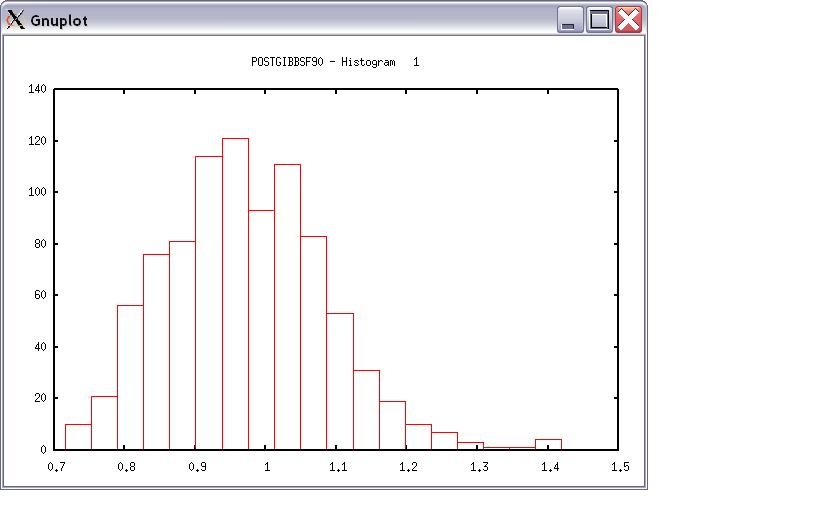
The distribution should be usually normal. print = 1; other graphs = 2; or stop = 0
This value could be used when calculating Bayes Factor or DIC.
Need more examples? |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||